Github: https://github.com/zhijie-group/LoPA
We introduce the Lookahead Parallel Decoding (LoPA) algorithm for diffusion large language models (dLLMs) inference. LoPA enables up to 10.1 tokens per forward pass (TPF) for state-of-the-art dLLMs—without compromising predictive performance. This represents an unprecedented degree of parallelism, a capability unmatched by previous dLLM decoding methods. Under multi-device deployment, our specialized system LoPA-Dist achieves a single-sample throughput of 1073.9 tokens per second.

Background
DLLMs show significant potential for high-speed inference, yet current confidence-driven decoding strategies are constrained by limited parallelism—typically achieving only 1-3 TPF on math and coding tasks [2, 3]. Our investigation identifies a key insight: during dLLM inference, the degree of parallelism fluctuates sharply with the prediction confidence, which is heavily influenced by the Token Filling Order (TFO). Consequently, standard strategies that greedily prioritize currently high-confidence positions may lead to suboptimal trajectories. To address this, we propose Lookahead Parallel Decoding (LoPA), a training-free, plug-and-play algorithm designed to actively explore superior TFOs to unlock higher parallelism.
Methodology
This section first explains the foundational Confidence-Driven Sampling used in regular dLLM inference [2, 3, 4] and then elaborates on LoPA.

Preliminary: Confidence-Driven Sampling for dLLMs
Confidence-driven sampling is a prevalent paradigm for current dLLMs to boost parallelism, adopted in models such as Fast-dLLM [2], D2F [3], and SDAR [4]. Specifically, given a sequence $x_t$ with a set of masked positions $M_t$, the dLLM model $p_{\theta}$ outputs a predictive distribution $p_{\theta}(\cdot \mid x_t)$. A candidate sequence $\hat{x}_0 \sim p_{\theta}(\cdot \mid x_t)$ is sampled, and a confidence function, $\text{Conf}(\cdot)$, assigns a score to each position $i \in M_t$. The set of positions to fill, $I_{fill}$, is then determined as:
$$I_{fill} = \begin{cases} \{i \in M_t \mid \text{Conf}(i) > \tau\} & \text{if } \{i \in M_t \mid \text{Conf}(i) > \tau\} \neq \emptyset \\ \{\arg\max_{i \in M_t} \text{Conf}(i)\} & \text{otherwise} \end{cases}$$
The algorithm then accepts the predictions according to $I_{fill}$ and moves to the next iteration.
LoPA

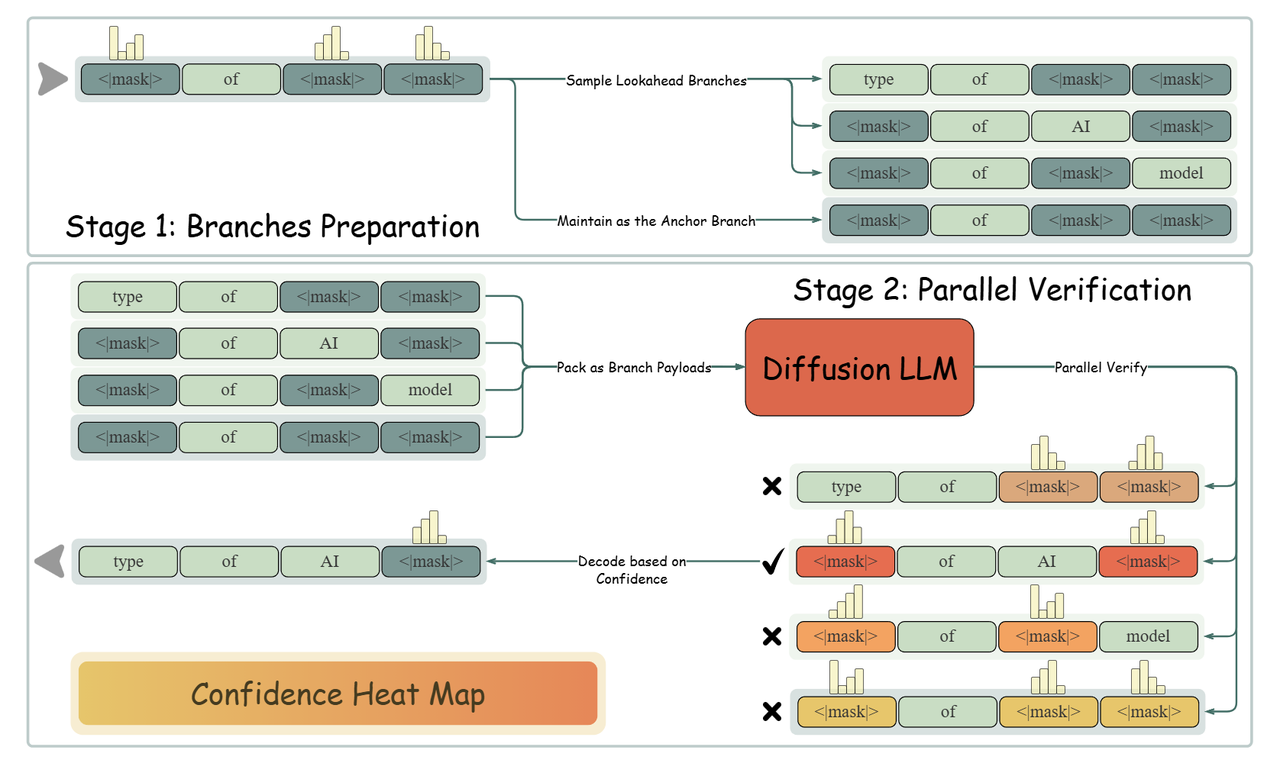
As shown in Figure 3, in every decoding iteration, LoPA looks ahead at multiple TFOs, yielding multiple sampling branches, and then identifies the branch with superior future parallel decoding potential.
Look ahead Multiple TFOs in Parallel
LoPA operates by generating multiple branches. First, it constructs an Anchor Branch ($B_0$) using the standard confidence-driven strategy (filling positions in $I_{fill}$).
LoPA is designed to explore one step further than this anchor branch. To ensure effective and reliable exploration, we prioritize sampling tokens with higher confidence, a strategy that has been proved in Fast-dLLM [2] to yield more stable predictions. Specifically, in addition to $B_0$, we generate $k$ competitive Lookahead Branches. We identify the top-$k$ positions from the anchor branch's unfilled set $M_{B_0}$ that possess the highest confidence scores. For each identified position, we sample it independently to create a distinct branch. This results in a set of $k$ new branches $\{B_1, \dots, B_k\}$, each with its own sequence $x_{B_j}$ and unfilled set $M_{B_j}$.
Branch Confidence-based Verification
Inspired by DeepConf [5], we design a branch confidence metric to guide the selection among candidate decoding paths. Formally, the confidence of a branch $B_j$ is defined as the average prediction confidence over its remaining unfilled positions $M_{B_j}$:
$$C(B_j) = \frac{1}{|M_{B_j}|} \sum_{i \in M_{B_j}} \text{Conf}(i)$$
A higher branch confidence indicates that more unfilled positions are likely to be accepted in the very next decoding step. This directly increases the number of tokens filled per iteration, thereby enhancing the overall parallelism. Beyond this mean confidence, branch confidence can also be quantified by other methods [5], such as applying a sliding window to assess local quality or averaging confidence over the least confident segment to identify weak links.
This verification mechanism offers distinct advantages. First, all candidate branches (Anchor + Lookahead) can be packed and verified within a single forward pass, with custom attention masks ensuring independent computation for each branch. Second, the logits computed during branch evaluation are directly reused in the next decoding step, eliminating the need for additional forward passes.
Application: integration with D2F
LoPA integrates seamlessly with D2F [3], the first open-source diffusion language model whose inference throughput surpasses that of autoregressive (AR) models. Our application of LoPA to D2F incorporates two key enhancements:
- Parallel Exploration in a Decoding Window: We treat all active blocks in D2F's pipeline as a single window where LoPA's branch exploration and lookahead verification operate. Replacing the original block-level causal attention with a full attention mechanism within this window reduces implementation complexity and enhances computational performance.
- System Integration and Performance: On the D2F-Dream model, LoPA achieves a TPF of up to 10.1. To leverage this parallelism, we developed a specialized multi-device inference system where LoPA achieves a throughput of 1073.86 tokens per second.
Results
Scaling Analysis of Branch Count
We analyzed the impact of the competitive branch count (k) on TPF and quality using D2F models fine-tuned on Dream[6] and DiffuCoder[7]. Results show TPF consistently improves with k; however, excessive k introduces fluctuations, attributed to the model prioritizing future confidence over local optimality. These results point to an optimal trade-off, where a carefully chosen k can maximize TPF while preserving quality.

As shown in the Figure 4, on GSM8K, LoPA scales the TPF of D2F-Dream to 10.1 while maintaining a score (73.8) superior to the Dream baseline (72.6). on HumanEval+, LoPA scales the TPF of D2F-DiffuCoder to 8.3 with marginal performance degradation, demonstrating a clear speed-accuracy trade-off.
Tables 1 and 2 below confirm this efficacy across multiple benchmarks.
| Model | Decoding algo | MBPP 3-shot | Math 4-shot | HumanEval 0-shot | GSM8K 4-shot | ||||
|---|---|---|---|---|---|---|---|---|---|
| TPF | Score | TPF | Score | TPF | Score | TPF | Score | ||
| Dream | vanilla | 1 | 56.2 | 1 | 33.7 | 1 | 55.5 | 1 | 72.6 |
| Dream | Fast-dLLM | 1.9 | 55.6 | 1.9 | 37.6 | 1.8 | 55.5 | 2.1 | 72.6 |
| Dream | LoPA | 3.3 | 54.8 | 3.4 | 37.0 | 2.9 | 53 | 3.1 | 73.3 |
| D2F-Dream | vanilla | 2.3 | 53.8 | 2.6 | 36.8 | 2.5 | 56.1 | 3.1 | 78.5 |
| D2F-Dream | LoPA | 5.4 | 56.0 | 8.0 | 35.2 | 6.3 | 56.1 | 10.1 | 73.8 |
| Model | Decoding algo | MBPP++ 0-shot | HumanEval++ 0-shot | ||
|---|---|---|---|---|---|
| TPF | Score | TPF | Score | ||
| DiffuCoder | vanilla | 1 | 61.9 | 1 | 65.2 |
| D2F-Diffucoder | vanilla | 2.2 | 61.9 | 2.2 | 65.9 |
| D2F-Diffucoder | LoPA | 6.7 | 61.6 | 8.3 | 64.0 |

System Throughput and Scalability
To fully exploit LoPA’s parallelism, we designed LoPA-Dist, a distributed inference system utilizing Branch Parallelism (BP).
The system distributes candidate branches across multiple GPUs for concurrent processing. We provide two specialized implementations:
- LoPA-Dist-NV (CUDA): Optimized for low latency using static KV cache and a two-phase update protocol (Pre-Write and Commit-Winner-Cache) to ensure consistency.
- LoPA-Dist-Ascend (Ascend 910C): Optimized for high throughput using hybrid parallelism and graph compilation to fuse element-wise operations.
As shown in Table 3, this design achieves near-linear scalability. On the Ascend platform, LoPA-Dist achieves a peak throughput of 1073.86 tokens/s.
| Model | Platform | MBPP | GSM8K | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Avg TPS | Max TPS | TPF | Latency | Avg TPS | Max TPS | TPF | Latency | ||
| D2F-Dream-Base | LoPA-Dist-NV | 708.48 | 1470.95 | 15.55 | 0.74 | 619.33 | 1299.25 | 13.16 | 0.85 |
| LoPA-Dist-Ascend | 1073.86 | 2400.12 | 11.92 | 0.78 | 856.46 | 2751.61 | 9.34 | 0.75 | |
| D2F-Dream-Instruct | LoPA-Dist-NV | 636.55 | 1811.71 | 9.52 | 0.14 | 609.90 | 1407.56 | 11.42 | 0.26 |
| LoPA-Dist-Ascend | 896.21 | 2586.73 | 8.64 | 0.11 | 897.10 | 1868.16 | 9.30 | 0.21 | |
| Model | Sys. Arch. | Settings | MBPP 3-shot | GSM8K 4-shot | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Avg TPS | Max TPS | Top-10 TPS | Score | Avg TPS | Max TPS | Top-10 TPS | Score | |||
| D2F-Dream-Base | LoPA-Dist-NV | S1 | 415.19 | 813.04 | 720.35 | 53.00 | 345.52 | 959.05 | 704.39 | 75.97 |
| S2 | 500.33 | 1185.77 | 874.87 | 53.40 | 402.52 | 913.12 | 842.83 | 73.54 | ||
| S3 | 550.37 | 1472.41 | 929.72 | 51.20 | 436.22 | 994.82 | 885.27 | 71.19 | ||
| S4 | 589.22 | 1576.93 | 1006.57 | 47.20 | 475.58 | 1203.61 | 1028.15 | 68.16 | ||
| S5 | 633.16 | 1408.40 | 963.67 | 46.80 | 516.85 | 1212.65 | 1055.08 | 66.79 | ||
| S6 | 678.26 | 1615.30 | 1150.65 | 41.80 | 546.72 | 1225.21 | 1121.57 | 64.14 | ||
| S7 | 466.27 | 784.33 | 764.52 | 51.80 | 416.91 | 909.82 | 841.95 | 71.27 | ||
| S8 | 545.90 | 1497.22 | 927.67 | 51.40 | 486.94 | 1176.14 | 959.37 | 68.39 | ||
| S9 | 588.00 | 1584.28 | 983.09 | 48.60 | 520.70 | 1250.67 | 1056.01 | 68.01 | ||
| S10 | 637.38 | 1552.56 | 1028.97 | 47.00 | 558.01 | 1115.26 | 1071.66 | 65.05 | ||
| S11 | 655.45 | 1535.10 | 1059.72 | 43.80 | 592.94 | 1315.93 | 1155.11 | 64.44 | ||
| S12 | 708.48 | 1470.95 | 1132.78 | 39.80 | 619.33 | 1299.25 | 1201.18 | 60.88 | ||
| LoPA-Dist-Ascend | S13 | 615.74 | 2173.7 | 1253.07 | 50.20 | 492.94 | 1337.60 | 1158.18 | 75.06 | |
| S14 | 753.78 | 2115.55 | 1397.85 | 50.20 | 589.77 | 1532.99 | 1342.79 | 72.86 | ||
| S15 | 842.97 | 2470.79 | 1538.16 | 50.00 | 644.34 | 1723.19 | 1476.24 | 70.58 | ||
| S16 | 923.35 | 2647.12 | 1513.54 | 45.60 | 700.14 | 1756.58 | 1601.93 | 68.69 | ||
| S17 | 994.88 | 2740.54 | 1739.85 | 43.00 | 754.75 | 2583.76 | 1848.82 | 64.29 | ||
| S18 | 1073.86 | 2400.12 | 1939.22 | 41.80 | 856.46 | 2751.61 | 2098.72 | 62.55 | ||
| D2F-Dream-Instruct | LoPA-Dist-NV | S1 | 305.74 | 959.00 | 695.88 | 52.80 | 330.62 | 758.34 | 674.53 | 78.17 |
| S2 | 373.23 | 1302.99 | 877.12 | 51.40 | 402.63 | 961.29 | 804.31 | 74.22 | ||
| S3 | 451.62 | 1419.09 | 1143.30 | 53.00 | 444.73 | 943.22 | 870.85 | 73.39 | ||
| S4 | 503.71 | 1779.60 | 1226.72 | 46.60 | 495.93 | 1131.64 | 941.23 | 72.48 | ||
| S5 | 568.65 | 1660.89 | 1317.38 | 42.00 | 540.76 | 1185.14 | 1033.60 | 68.99 | ||
| S6 | 615.95 | 1951.86 | 1542.82 | 37.60 | 568.75 | 1352.22 | 1139.06 | 65.88 | ||
| S7 | 325.15 | 697.49 | 620.42 | 50.80 | 379.42 | 839.65 | 710.10 | 75.28 | ||
| S8 | 408.37 | 1182.69 | 866.90 | 51.00 | 449.56 | 934.55 | 838.35 | 75.13 | ||
| S9 | 465.55 | 1097.40 | 1016.91 | 50.60 | 497.47 | 1172.31 | 946.98 | 74.75 | ||
| S10 | 544.72 | 1542.99 | 1145.55 | 46.80 | 539.28 | 1147.95 | 1021.96 | 71.34 | ||
| S11 | 591.57 | 1578.00 | 1204.05 | 42.20 | 580.04 | 1292.18 | 1132.19 | 66.94 | ||
| S12 | 636.55 | 1811.71 | 1500.59 | 36.00 | 609.90 | 1407.56 | 1159.28 | 65.50 | ||
| LoPA-Dist-Ascend | S13 | 412.90 | 911.73 | 911.73 | 50.80 | 515.01 | 1235.84 | 1090.45 | 76.12 | |
| S14 | 525.66 | 1546.34 | 1143.37 | 48.40 | 619.58 | 1424.32 | 1310.35 | 75.36 | ||
| S15 | 625.53 | 1729.78 | 1435.06 | 46.20 | 689.89 | 1644.74 | 1356.36 | 72.63 | ||
| S16 | 716.19 | 1780.41 | 1558.00 | 43.80 | 770.78 | 1589.69 | 1480.56 | 71.49 | ||
| S17 | 796.65 | 1798.14 | 1687.69 | 39.80 | 837.21 | 1782.80 | 1517.90 | 67.78 | ||
| S18 | 896.21 | 2586.73 | 2086.04 | 36.40 | 897.10 | 1868.16 | 1642.72 | 66.87 | ||
The results illustrate the trade-off between inference throughput and generation quality across varying branch configurations and system backends.
Future Works
We are working on a new inference framework for dLLMs named Diffulex, which is flexible and easy to extend. Diffulex supports multiple decoding strategies including D2F, BlockDiffusion, and Fast-dLLM-v2, which is soon to be released. You can find the code here.
We will explore adapting LoPA to SDAR and other confidence-driven diffusion language models to further demonstrate its generalizability and effectiveness across diverse model architectures.
Reference
[1] Nie, Shen, et al. "Large language diffusion models." arXiv preprint arXiv:2502.09992 (2025).
[2] Wu, Chengyue, et al. "Fast-dllm: Training-free acceleration of diffusion llm by enabling kv cache and parallel decoding." arXiv preprint arXiv:2505.22618 (2025).
[3] Wang, Xu, et al. "Diffusion llms can do faster-than-ar inference via discrete diffusion forcing." arXiv preprint arXiv:2508.09192 (2025).
[4] Cheng, Shuang, et al. "SDAR: A Synergistic Diffusion-AutoRegression Paradigm for Scalable Sequence Generation." arXiv preprint arXiv:2510.06303 (2025).
[5] Fu, Yichao, et al. "Deep think with confidence." arXiv preprint arXiv:2508.15260 (2025).
[6] Ye, Jiacheng, et al. "Dream 7b: Diffusion large language models." arXiv preprint arXiv:2508.15487 (2025).
[7] Gong, Shansan, et al. "DiffuCoder: Understanding and Improving Masked Diffusion Models for Code Generation." arXiv preprint arXiv:2506.20639 (2025).
BibTeX
@misc{xu2025lopascalingdllminference,
title={LoPA: Scaling dLLM Inference via Lookahead Parallel Decoding},
author={Chenkai Xu and Yijie Jin and Jiajun Li and Yi Tu and Guoping Long and Dandan Tu and Tianqi Hou and Junchi Yan and Zhijie Deng},
year={2025},
eprint={2512.16229},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2512.16229},
}