LongCat-Flash[1] 近期展示了一种token级别自适应的MoE的大规模部署方案。该方案利用零计算(恒等)专家,在560B MoE模型中,每个token激活18.6B~31.3B的参数量(平均约27B)。每一层混合了512个真专家和256个零计算专家,每次选择top-12的专家,并且由于采用了PID式预算控制器,平均真专家选择数量稳定在约8个。设备级负载均衡和ScMoE保证了系统的效率。他们将该模型呈现为一个具有强大吞吐量/成本指标的非思考模型。
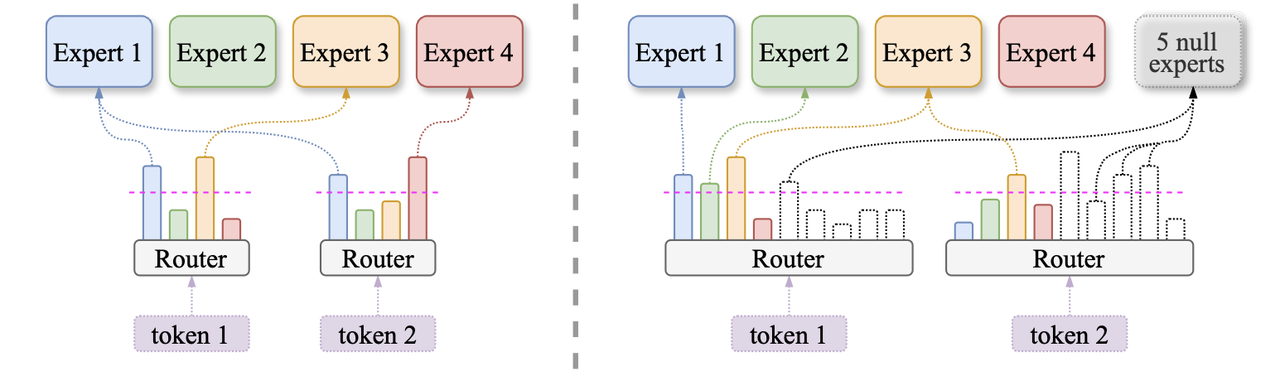
这种设计——添加空专家并增加top-k值,从而使每个token使用可变数量的真实专家——正是AdaMoE背后的核心思想。
太长不看版
AdaMoE 通过向专家池中添加一组 “空专家”(null experts)(其计算开销为零),为混合专家模型(MoE)带来了Token级别的自适应专家选择能力。
- 在
top-k路由范式下,当一个Token被路由到“空专家”时,它实际上激活了更少的真实专家。这使得每个Token所激活的真实专家数量,在保持平均计算预算不变的前提下,实现了自适应。 - 我们对负载均衡损失函数(load‑balancing loss)进行了微调(将所有“空专家”视为一个聚合的计算单元),并采用了一个简单的退火策略。AdaMoE在降低了计算量(FLOPs)的同时,保持甚至提升了模型的准确率。例如,在Mixtral‑8×7B模型和ARC‑C数据集上的实验显示:计算量降低了14.55%,而准确率提升了1.69%。
为何专家选择需要Token级别的自适应?
top-k 模式转向Token级别的自适应模式,其根本原因在于一个关键的观察:并非所有Token在计算上都生而平等。在一段文本中,不同Token所蕴含的信息量和处理的复杂度存在巨大差异。传统的MoE模型强制每个Token激活固定数量的专家,这种统一的计算分配方式忽略了Token间的差异,从而导致了计算资源的低效分配。
我们为此提供了实验性的证据。我们分析了Mixtral-8x7B(一个采用固定top-2路由的模型)的路由概率分布,并发现了两种关键模式:
- 大量Token的路由概率高度集中于单个专家,这表明激活第二个专家通常是多余的;
- 另有相当一部分Token的概率更均匀地分布在多个专家上,这意味着它们可能需要两个甚至更多专家的计算能力才能被有效处理。
这一发现有力地证明,固定的 top-k策略是次优的,它对简单的Token造成了过度计算,而对复杂的Token则可能计算不足。
借助“空专家”实现自适应路由
AdaMoE 通过引入 “空专家”(null experts)来实现Token级别的自适应专家选择。我们将其定义为一种不执行任何操作的单元,处理Token特征所需的计算量(FLOPs)为零。在大型语言模型的实践中,常见的零计算操作包括常数零映射和恒等映射(为简化起见,我们在后续讨论中默认采用零映射作为“空专家”的实现)。
我们的机制运行如下:
- 在原有的
n个真实专家之外,将专家集合扩展m个“空专家”。 - 略微增加路由器的
top-k值(例如,从 2 增加到 3 或 4)。这样,每个Token选出的top-k专家中就可能包含一部分“空专家”。 - 实现计算的自适应:如果
top-k专家中包含r个“空专家”,那么该Token实际上只使用了k-r个真实专家。 - 进行合理的负载均衡:在计算负载均衡损失时,我们将所有“空专家”聚合为单一的计算单元(因为没有必要在完全等价的“空专家”之间强制实现均衡)。
- 在
top-k选择之后,仅对真实专家进行归一化,以确保输出的尺度与标准的MoE模型保持一致。

主要实验结果

从论文走向实践
我们备受鼓舞地看到,“空专家”这一概念并非仅仅停留在理论层面,它已被业界前沿的大型语言模型所采纳和实现。LongCat-Flash的技术报告中,就将 “零计算专家”(zero-computation experts)列为一项关键的架构创新,并引用了我们的论文。
该报告解释说,这一机制使得模型能够“根据Token的重要性为其分配动态的计算预算”,根据上下文的不同,为每个Token激活动态变化的参数。这一直接的工业应用,彰显了我们提出的自适应路由策略在现实世界中的实用性和可扩展性。
此外,LongCat-Flash 还引入了多种优化技术,以应对自适应专家选择所带来的通信和负载均衡挑战——这进一步证明了我们的方法在大型系统中的可行性。
引用我们的工作
如果您认为我们的工作对您有所启发,欢迎引用我们的论文:
@inproceedings{zeng-etal-2024-adamoe,
title = "AdaMoE: Token-Adaptive Routing with Null Experts for Mixture-of-Experts Language Models",
author = "Zeng, Zihao and
Miao, Yibo and
Gao, Hongcheng and
Zhang, Hao and
Deng, Zhijie",
editor = "Al-Onaizan, Yaser and
Bansal, Mohit and
Chen, Yun-Nung",
booktitle = "Findings of the Association for Computational Linguistics: EMNLP 2024",
month = nov,
year = "2024",
address = "Miami, Florida, USA",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2024.findings-emnlp.361/",
doi = "10.18653/v1/2024.findings-emnlp.361",
pages = "6223--6235"
}
参考文献
[1] Team, Meituan LongCat, et al. “LongCat-Flash Technical Report.” arXiv preprint arXiv:2509.01322 (2025).