LongCat-Flash[1] just showed a clean, large-scale deployment of token-adaptive MoE with zero-computation (identity) experts—-activating 18.6–31.3B parameters per token (~27B on average) inside a 560B MoE. Each layer mixes 512 FFN experts + 256 zero-compute experts, the router selects Top-12, and the average true-expert picks settle around ~8 thanks to a PID-style budget controller; device-level load balancing and ScMoE (shortcut-connected MoE) keep the system efficient. They present the model as a non-thinking foundation model with strong throughput/cost metrics.
That design—adding null experts and bumping top-k so each token uses a variable number of true experts—is precisely the idea behind AdaMoE.
TL; DR
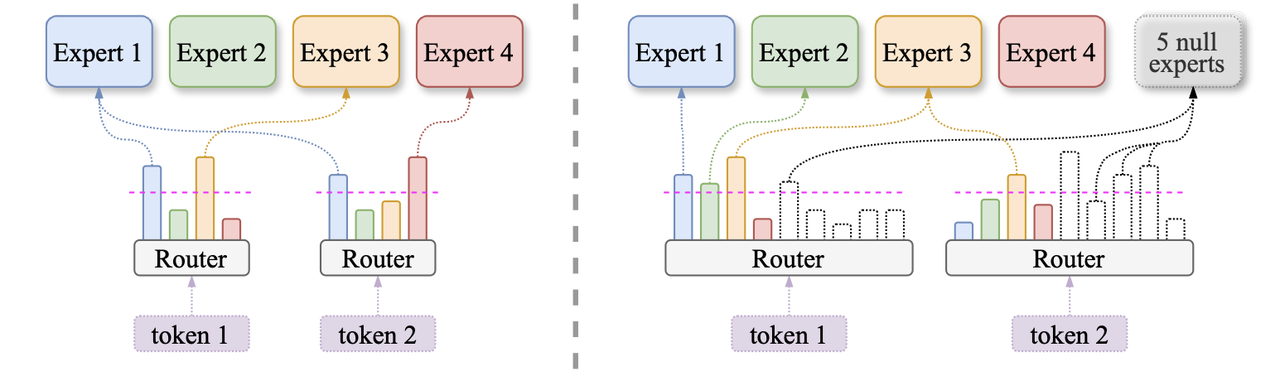
AdaMoE adds a set of null experts (with zero compute) to the expert pool to enable token-adaptive expert choice for MoE.
- Under the top-k routing paradigm, tokens that route to null experts effectively use fewer true experts, making the number of true experts per token adaptive under the same average budget.
- With a minor tweak to the load‑balancing loss (treat all nulls as one averaged bucket) and a simple annealing schedule, AdaMoE reduces FLOPs while maintaining or improving accuracy (e.g., on Mixtral‑8×7B/ARC‑C: −14.55% FLOPs with +1.69% accuracy).
Why Expert Selection Should Be Adaptive at the Token Level

We provide empirical evidence for this variance. We analyzed the routing probability distributions in Mixtral-8x7B, a model with a fixed top-2 router. Our analysis revealed two key patterns:
- A large fraction of tokens had routing probabilities that were highly concentrated on a single expert, indicating that the activation of a second expert was often superfluous;
- A significant portion of other tokens had their probabilities distributed more evenly across multiple experts, suggesting that they required the computational capacity of two or even more experts for effective processing.
This finding demonstrates that a static top-k strategy is suboptimal, leading to computationally excessive allocations for simple tokens and potentially insufficient allocations for complex ones.
“Null Experts” for Adaptive Routing
AdaMoE achieves token-adaptive expert selection by incorporating null experts, which are defined as an empty operation requiring zero FLOPs to process the token feature. In the context of LLMs, common operations satisfying this requirement include a constant zero mapping and an identity mapping (we take the zero mappings null expert as the default choice in the following just for simplicity).
Our mechanism operates as follows:
- Extends the expert set with m null experts (besides n true experts).
- Slightly increases the router’s top‑k (e.g., from 2 → 3/4). Now each token’s top‑k may include some nulls.
- Makes compute adaptive: if top‑k includes r nulls, the token uses only k-r true experts.
- Balances sensibly by aggregating all nulls into a single bucket in the load‑balance loss (don’t force balance between identical nulls).
- Normalizes over true experts only after top‑k so the output scale matches vanilla MoE.

Main Results

From Paper to Production
We are also encouraged to see that the concept of null experts is not merely theoretical, but has been implemented in state-of-the-art LLMs. The technical report for LongCat-Flash identifies zero-computation experts as a key architectural innovation and cites our paper.
The report explains that this mechanism enables the model to “allocate a dynamic computation budget to important tokens based on their significance,” activating a variable range of parameters for each token depending on context. This direct industrial application underscores the practicality and scalability of the adaptive routing strategy we proposed.
In addition, LongCat-Flash introduces several optimization techniques to address communication and load-balancing challenges associated with adaptive expert selection—further demonstrating the viability of our approach in large-scale systems.
Cite Our Work
If you find our work useful, please cite our paper:
@inproceedings{zeng-etal-2024-adamoe,
title = "AdaMoE: Token-Adaptive Routing with Null Experts for Mixture-of-Experts Language Models",
author = "Zeng, Zihao and
Miao, Yibo and
Gao, Hongcheng and
Zhang, Hao and
Deng, Zhijie",
editor = "Al-Onaizan, Yaser and
Bansal, Mohit and
Chen, Yun-Nung",
booktitle = "Findings of the Association for Computational Linguistics: EMNLP 2024",
month = nov,
year = "2024",
address = "Miami, Florida, USA",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2024.findings-emnlp.361/",
doi = "10.18653/v1/2024.findings-emnlp.361",
pages = "6223--6235"
}
Reference
[1] Team, Meituan LongCat, et al. “LongCat-Flash Technical Report.” arXiv preprint arXiv:2509.01322 (2025).